Demo to Chris Mellish 2
Showed Chris the system working with ontology comparisons. He warned us to watch our choice of phrasings, for example giving a measure of information density is only as reliable as our ability to extract information from text.
Further work to be done to the system before performing evaluations:
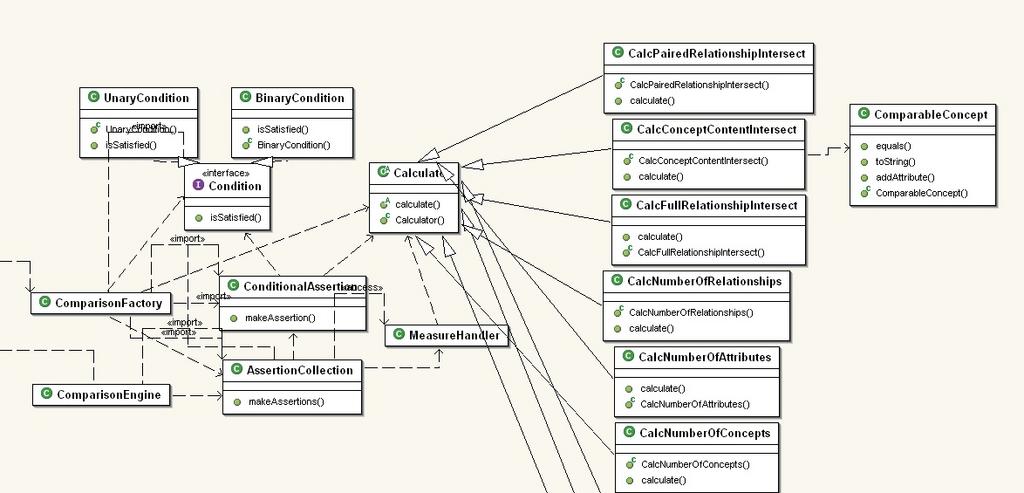
Add the use of lexical and structural analysis to calculate measure statistics for use in comparisons
Add functionality for an overlap KB to be built from two KBs being compared: the overlap KB will contain all that is common to both original KBs.
Check the entire project for code worth cleaning.
Refine Learn GUI.
Further work to be done to the system before performing evaluations:
Add the use of lexical and structural analysis to calculate measure statistics for use in comparisons
Add functionality for an overlap KB to be built from two KBs being compared: the overlap KB will contain all that is common to both original KBs.
Check the entire project for code worth cleaning.
Refine Learn GUI.
posted by Steven Morrison at 4:11 PM
0 comments
![]()